从开源 ASR 说起
最近 NVIDIA 在 Hugging Face 上放出了 Nemotron 3.5 ASR Streaming,一个 600M 参数的流式语音识别模型。
它和之前文章里写过的 Nemotron 3 Ultra 大语言模型不是一回事——这个 ASR 专注做一件事:语音转文字。而且它支持实时流式处理,一个模型覆盖 40 种语言,不需要逐个语言换模型。
我关注它,不是因为 NVIDIA 牌子的光环,而是因为它恰好卡在几个我比较在意的交叉点上:
- 本地可跑——600M 参数(0.6B),当代 GPU 或者哪怕 Apple Silicon Mac 应该都能推理
- 流式架构——不像传统 ASR 要等说完一整句话才出结果,它是边听边出的
- 开源权重——Apache 2.0 系的开源协议,没有 API 依赖,是真的本地部署路线
- 中文支持——zh-CN 在”广覆盖”层级,开箱可用,但不像英文那么精准
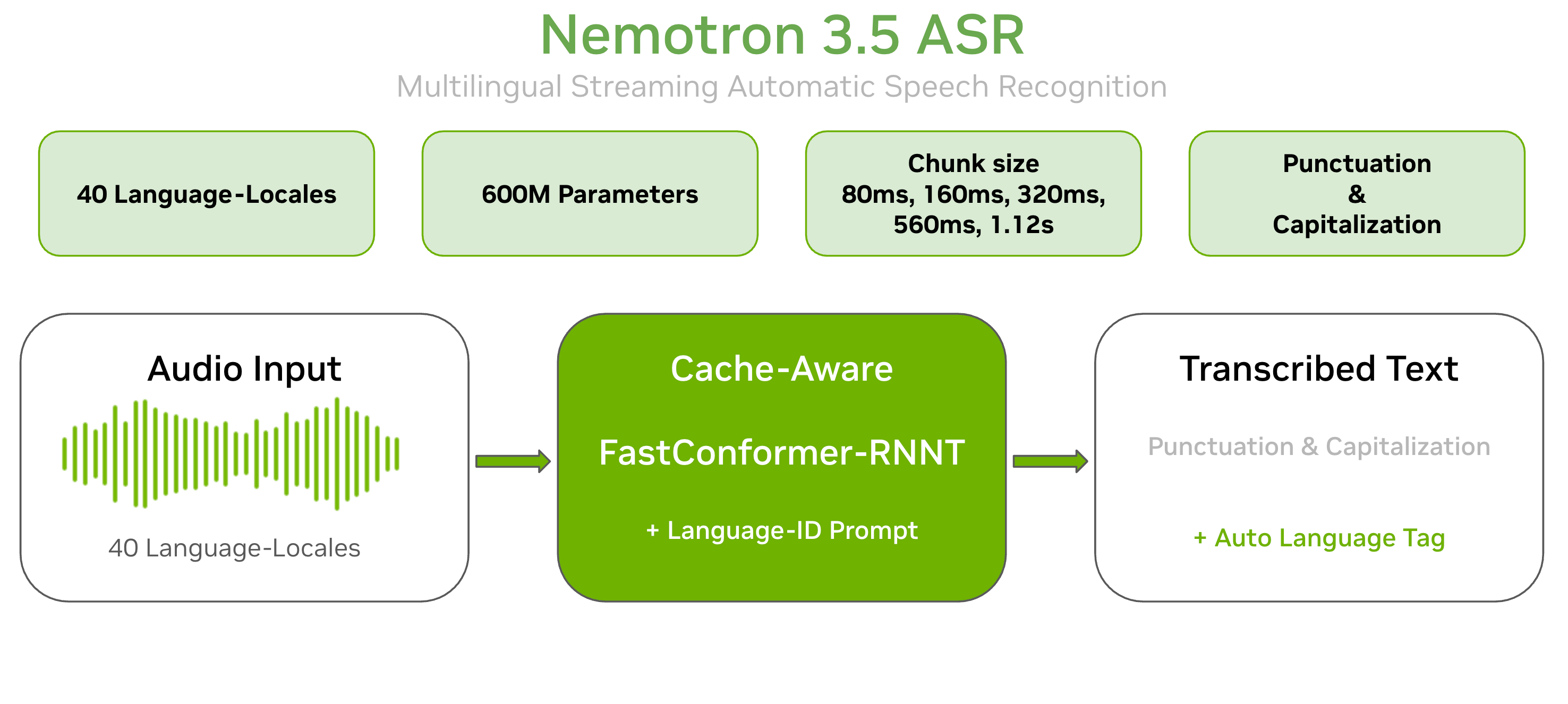
Nemotron 3.5 ASR 概览:多语言输入 → FastConformer-RNNT → 带标点和语言标签的文字输出(来源:NVIDIA / Hugging Face)
这次发布的到底是什么
Nemotron 3.5 ASR Streaming(模型名:nvidia/nemotron-3.5-asr-streaming-0.6b)是 NVIDIA 第三代的语音识别模型,架构是 FastConformer-CacheAware-RNNT。
说人话就是:它用了缓存感知的编码器+RNNT 解码器组合,不需要等音频完整传输就能输出文字。延迟可以调节,最低到 80ms(接近实时),最高 1.12s(追求最高准确率),同一个模型不用重新训练。
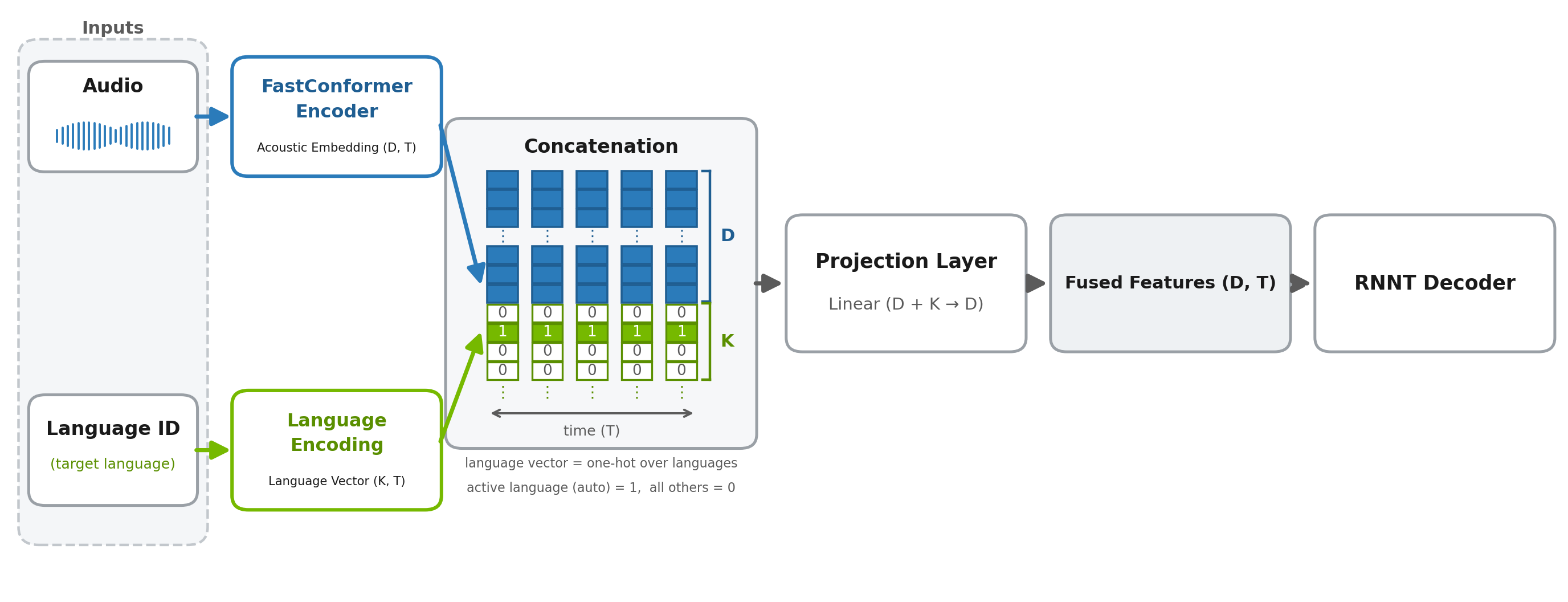
Nemotron 3.5 ASR 架构:FastConformer 编码器与语言 ID 编码拼接后投影到 RNNT 解码器(来源:NVIDIA / Hugging Face)
最实用的设计是:支持语言自动检测。你给它一段混合多种语言的录音,它能自动识别并切换识别语言。
从具体数据来看,它在 FLEURS 测试集上的表现:
最佳语言(已知语言 ID 输入,80ms 低延迟模式)
- 西班牙语:WER 4.87%
- 意大利语:5.23%
- 葡萄牙语:6.29%
- 印地语:8.13%
- 韩语(CER):7.59%
中文(zh-CN)表现:CER 约 20.56%(80ms 模式,已知语言),属于”广覆盖”层级——能识别,但达不到精准级别。
对比主流的商业语音识别 API,这个数字不算惊艳,但考虑到它 600M 参数就能在本地流式跑,而且是一个模型扛 40 种语言,我觉得这个取舍可以接受。
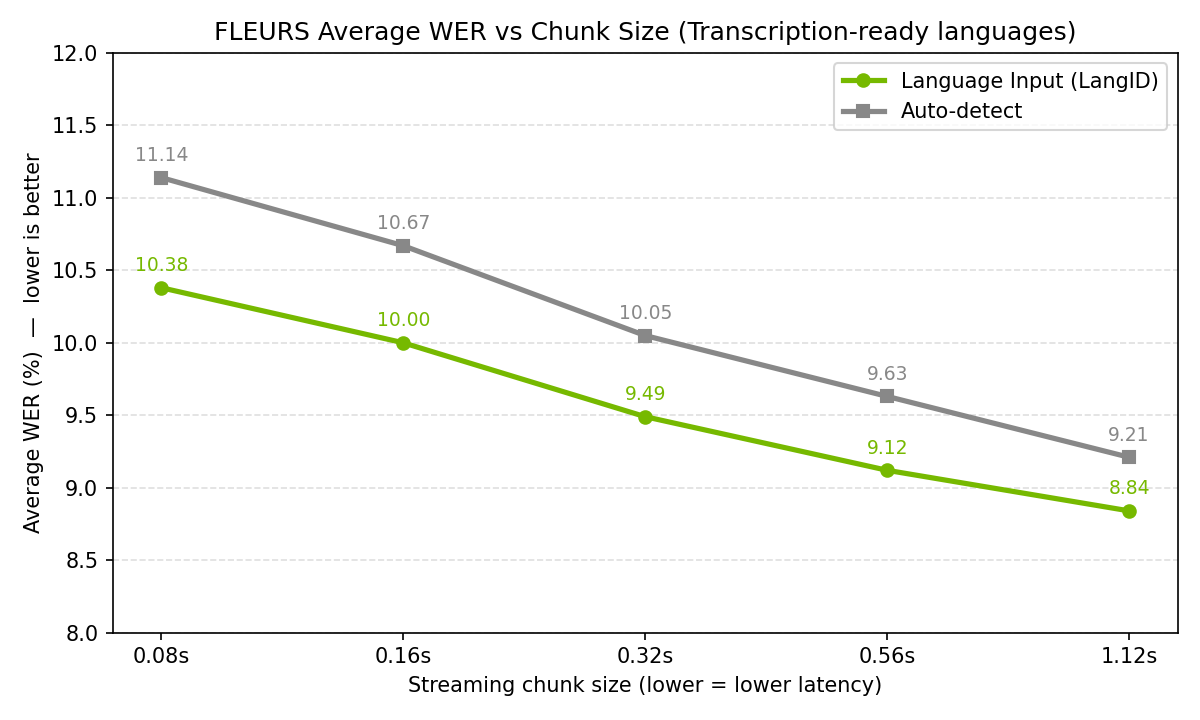
FLEURS 测试集平均 WER vs 流式 chunk 大小:LangID 与 Auto-detect 模式对比(来源:NVIDIA / Hugging Face)
对我来说值得注意的点
1. 本地部署的可能性
这个模型需要 NeMo 框架(NVIDIA 的开源语音 AI 框架)来跑推理。NeMo 本身支持 GPU,也支持 TensorRT 优化。
对于 ARM Mac 用户来说,目前没法直接跑 NeMo 的完整流水线——NeMo 的 CUDA 依赖决定了它主要还是面向 NVIDIA GPU 的。但这不代表完全不能用:一个可能路径是走 ONNX 导出后用 CPU 推理,另一个等待社区封装。
2. 微调潜力
NVIDIA 这次同步发了一篇详细的微调指南(Hugging Face Blog),讲了如何对新的语言、领域(医疗、法律)、口音做微调。
关键数据点:
- 用 ~2000 小时数据微调后,希腊语 WER 从 35% 降到 24%(改进 32%)
- 保加利亚语 WER 从 22% 降到 15%(改进 31%)
- 改进幅度最大的恰恰是基础准确率最低的语言
这个模式对中文来说也是类似的:官方基线的 CER 20% 不算好,但如果你有领域内的中文语音数据做微调,应该能显著提升。
3. 流式延迟的动态调优
这个模型让我觉得比较聪明的地方是:延迟和准确率的平衡可以在推理时动态调整,不需要重新训练。
- 80ms:极低延迟,适合实时语音助手
- 160ms:低延迟,适合交互式对话
- 320ms:中等延迟,适合对话记录/会议
- 560ms:较高延迟,适合高准确率场景
- 1.12s:最高延迟,适合最高准确率
同一份训练好的 checkpoint,换一个参数就能切换场景。
几个实际制约
- NeMo 生态较重——不是 pip install 直接跑那么简单,需要 clone 整个 NeMo 仓库,走它的 pipeline。对于想”下个模型立刻用”的折腾党来说,门槛有点高
- 中文精准度仍需微调——20% 的 CER 在生产环境不太够用,尤其对于中文这种同音字密集的语言
- 协议是 OpenMDW-1.1——不是纯 Apache 2.0,需要确认商用条款是否符合你的场景
- NIM 部署版本还未出——NVIDIA 后续会提供 gRPC 流式部署方案(NIM),但目前还在路上
我的判断
Nemotron 3.5 ASR 不是一个”装上就能替代 Whisper”的东西——Whisper 的中文准确率、生态成熟度和使用便利性都明显更高。
但它代表了一个很有趣的方向:多语言流式 ASR 的小型化。600M 参数就能做到 40 语言的实时转录,这在一年前还是需要更大模型或者商业 API 才能实现的。
如果你正在做一个多语言语音助手、或者需要本地的实时字幕方案,而且你的主要语言不是中文(英/西/意等优先支持的语言),那么这个模型值得关注后续的社区封装进展。如果你主要做中文 ASR,目前 Whisper 仍然是更务实的选择。
等后续 NIM 部署包或者社区 Docker 镜像出来后,我如果真去试了,再补一篇实操记录。