如果你最近打开终端跑了 ollama update,可能没注意到——Ollama 在六月份一口气发了 7 个版本(v0.30.2 到 v0.30.9),几乎每两天一个更新。从底层引擎重构到新模型支持、从 Apple Silicon 性能调到提示缓存优化,这次的更新密度和质量都相当高。
这篇文章按时间线梳理每个版本的关键变化,方便你判断哪些更新值得关注、哪些坑需要注意。

v0.30.0:基础大版本,GGUF 正式入场
6 月 2 日发布的 v0.30.0 是整个系列的基石。核心变化有三件事:
1. llama.cpp 深度整合,性能与兼容性双丰收
Ollama 在 v0.30.0 中与 llama.cpp 上游最新成果完成了深度对齐。此前因算子适配不足而无法运行的模型变体——比如社区中各类基于 GQA 改进、融合特定位置编码的 GGUF 文件——现在大多可以正常加载推理。
更关键的是性能提升。llama.cpp 社区过去半年在 KV 缓存管理、prompt 处理效率和批量推理逻辑上的优化,全部纳入了这一版。长文本总结、代码库分析等重度场景中,prefill 阶段的延迟会明显降低。
2. Apple Silicon 的 MLX 引擎得到”增强”
这里有个容易误解的点:v0.30.0 不是用 llama.cpp 替换了 MLX,而是让两者协同工作。Ollama 现在能更智能地评估 Mac GPU 内存压力,将部分兼容性要求较高的算子交由 llama.cpp 后端联合处理。也就是说,入门款 M1/M2 MacBook Air、低配 Mac mini 这些之前被 MLX 加速”拒之门外”的设备,现在也能享受 GPU 加速了。
3. Hugging Face GGUF 模型原生支持
这是对生态影响最大的特性。之前想从 Hugging Face 拉一个 GGUF 模型到 Ollama,得手动下载文件、写 Modelfile、指定本地路径。现在 Ollama 对 GGUF 格式实现了原生识别与自动配置解析——直接 ollama create -f Modelfile 指向 GGUF 文件就能跑。社区中那些针对角色扮演、中文古诗、医疗问答等场景微调的小众模型,现在都可以无痛接入。
社区项目 Unsloth 的微调模型、LiquidAI 的 LFM 系列、Prism 的 Bonsai 系列——这些都是 v0.30.0 开始能直接在 Ollama 里跑的。
三个已知问题(升级前必看)
Ollama 官方在更新公告中明确列出了三项已知问题:
- laguna-xs.2 不支持 Windows/Linux:该模型在非 macOS 平台上存在兼容性缺陷
- llama3.2-vision 暂不支持:视觉模型的图像编码器和跨模态注意力机制仍在适配中
- nomic-embed-text 强制小写:这是破坏性变更!升级后所有基于旧版 Ollama 生成的嵌入向量与新版本不兼容。如果你依赖向量数据库(Chroma、Pinecone 等),升级后必须全量重索引
第三点尤其重要——升级前请确认你的 RAG 系统的重索引方案。
v0.30.2 ~ v0.30.7:新模型、新工具、桌面端
这一波密集更新带来了大量新模型支持:
- v0.30.2(6月3日):默认支持 Radeon 8060S 集显,AMD 用户受益
- v0.30.3(6月3日):Gemma 4 12B 模型支持。Google 的高性能多模态模型,可直接在笔记本上运行
- v0.30.4(6月3日):NVIDIA Nemotron-3-Ultra 支持,专为高吞吐量推理和长周期 agent 工作流设计。同时修复了多模态模型在 llama.cpp 后端无法使用 GPU 的问题
- v0.30.5(6月4日):修复 Gemma 4 在 x86/CUDA 上的浮点异常崩溃;
ollama launch hermes-desktop支持启动 Hermes Desktop - v0.30.6(6月5日):Gemma 4 系列新增 量化感知训练(QAT) 权重版本,内存占用大幅降低。包含 gemma4:12b-it-qat 等五个 QAT 版本。同时
ollama launch omp集成 Oh My Pi AI 编程智能体 - v0.30.7(6月7日):Hermes Desktop 正式上线,
ollama launch hermes-desktop即可启动原生桌面界面,支持对话管理、集成和消息应用
v0.30.8 ~ v0.30.9:快照系统与缓存优化
最后的两个版本把重点放在了稳定性和性能上。
v0.30.8(6月12日):
- 提示词缓存解耦:将提示词缓存与上下文偏移分离,提升 KV 缓存复用效率。长期对话和重复任务场景中,预计性能提升 15-25%
- MLX 快照功能:在提示词处理和推测解码过程中自动创建快照。如果推理中断,可以从快照恢复而非从头开始——对 Mac 这种统一内存架构的设备特别有用
- 循环模型支持增强:通过门控 delta 内核实现边界级状态管理,改善需要长期上下文的对话 AI 和代码生成场景
v0.30.9(6月15日,前天刚出):
- 新增 Cohere2Moe 架构支持
- 修复
ollama launch claude等编程 agent 场景下只输出单个 token 的问题 - 新增单条消息大小校验:超过上下文窗口的消息会直接返回错误,而非静默失败
6 月 11 日的独立重磅:MLX 引擎性能飞跃
除了版本迭代,Ollama 还在 6 月 11 日发布了一篇专门的技术博客,宣布 MLX 引擎的性能大幅提升。
NVFP4 量化:4-bit 精度下质量损失减半
Ollama 的 MLX 引擎新增了对 NVIDIA NVFP4 格式的支持。NVFP4 是一种模型优化型 4-bit 量化格式,相比常见的 q4_K_M,在 Gemma 4 12B 上的质量损失(perplexity 差距)大约减半,同时保持了相当的推理速度。这对追求质量的本地部署场景是个好消息——你用差不多的显存,得到更接近 BF16 精度的输出。
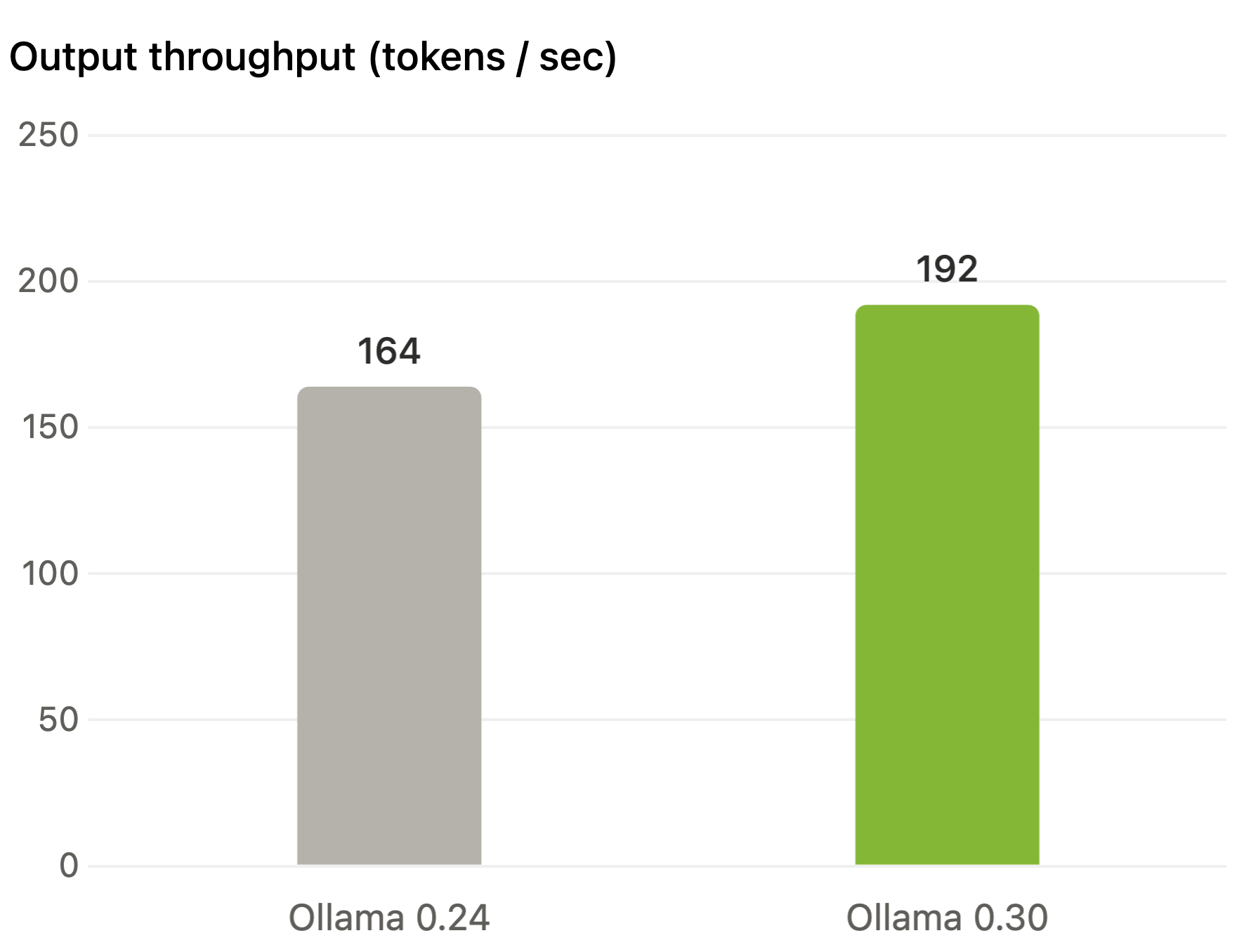
输出速度提升 20%
通过对多个操作融合为单一 Metal kernel,以及重构 GPU 后端采样逻辑,MLX 引擎的输出速度最高提升了 20%。
快照系统:Agent 工作流的关键基础设施
这是一个容易被忽视但实际影响巨大的改进。在 agent 工作流中,每次工具调用都是一次新的请求,需要重新处理整个对话历史(系统提示词、工具定义、所有已读文件)。Ollama 的新快照系统在对话的关键节点保存模型状态:
- 多 agent 场景:agent 交给 subagent 后再恢复,共享的上下文只需处理一次
- Thinking 模型:推理 token 生成后被丢弃,下轮请求从保存的快照恢复,避免重复处理
- 分支与重试:对话分叉时,只需处理新方向的内容
用户该怎么升级?
# 一行搞定
ollama update
# 确认版本
ollama --version
几点建议:
- Mac 用户(特别是入门款 M1/M2):这次升级最值得。MLX 增强 + NVFP4 + 快照系统,三重利好
- NVIDIA 显卡用户:无风险升级,直接吃 20% 性能红利
- 用 nomic-embed-text 做 RAG 的:升级前务必准备好重索引方案,不要在生产环境直接升
- 等视觉模型的:llama3.2-vision 还没适配完,继续等
一句话总结
Ollama v0.30.x 系列是本地 AI 工具链的一次重要能力升级:底层引擎更稳、模型生态更开放、Apple Silicon 性能更强。如果你在用 Ollama 跑本地模型,这一波更新值得升。